Una de las características destacadas de las plantillas en AI Content Labs es la posibilidad de configurar parámetros adicionales de la IA para obtener una mayor personalización en los resultados generados. A continuación, se detallan las configuraciones básicas y avanzadas disponibles.
Configuración Básica
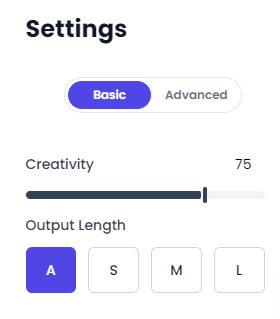
Consta de dos parámetros: Creatividad y Longitud de Salida:
Creatividad
El nivel de creatividad del contenido generado puede ajustarse según tus necesidades:
- Baja Creatividad: Más preciso, conciso y simple.
- Ejemplo: Si estás escribiendo un manual técnico, una configuración de baja creatividad generará contenido que sea directo y fácil de seguir, enfocándose en información clara y factual.
- Creatividad Media: Equilibrado, informativo y descriptivo.
- Ejemplo: Si estás creando un resumen de un evento histórico, una configuración de creatividad media proporcionará una visión general, detallada y atractiva, mezclando hechos con narrativas interesantes.
- Alta Creatividad: Creativo, original e imaginativo.
- Ejemplo: Si estás escribiendo una novela de ciencia ficción, una configuración de alta creatividad generará contenido lleno de ideas innovadoras, personajes únicos y tramas cautivadoras, explorando nuevos y poco convencionales temas.
Puedes experimentar con estas configuraciones para encontrar la que mejor se adapte a tu propósito.
Longitud de Salida
Define la extensión del contenido generado de acuerdo a tus necesidades:
- Auto (A): La longitud de la salida se calculará automáticamente, basada en la longitud del prompt y la capacidad del modelo.
- Corta (S): Produce cerca de 100 palabras. Ideal para actualizaciones breves en redes sociales, respuestas concisas en correos electrónicos o descripciones cortas de productos.
- Media (M): Alrededor de 300 palabras. Adecuada para publicaciones más extensas en redes sociales, introducciones de boletines o descripciones breves de productos.
- Larga (L): Genera cerca de 750 palabras. Perfecta para entradas breves en blogs, artículos de longitud moderada o resúmenes extensos.
Selecciona la longitud que mejor se alinee con tus necesidades y el contexto de tu proyecto.
Configuración Avanzada
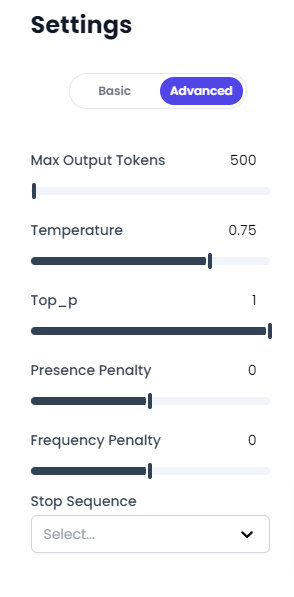
Permite un ajuste más preciso de los parámetros en los modelos de IA, incluyendo:
Max Output Tokens
Este parámetro, conocido como «max_tokens», establece el número máximo de tokens que la IA puede generar en su respuesta. Un token puede ser una pieza de texto, desde un carácter hasta una palabra completa. El recuento total de tokens, incluyendo tu prompt y la respuesta de la IA, no debe superar el límite del modelo.
El número de tokens influye en varios aspectos:
- Costo de la llamada API: Considera los tokens como la ‘moneda’ de generación de texto. Cuanto mayor sea el número, más costosa será la llamada.
- Tiempo de la llamada API: Generar más tokens requiere más tiempo. Para respuestas rápidas, considera un número menor.
- Viabilidad de la llamada API: Si excedes el límite de tokens del modelo, la llamada fallará.
Tanto los tokens de entrada como los de salida cuentan para estas cantidades. Por ejemplo, si tu llamada API usó 10 tokens en la entrada del mensaje y recibiste 20 tokens en la salida del mensaje, se te facturará por 30 tokens.
Recomendaciones de Uso:
- Ajusta este parámetro según tus necesidades. Si buscas respuestas largas y detalladas, usa un valor alto. Si buscas respuestas rápidas y concisas, usa un valor bajo.
- Ten en cuenta que un valor muy alto de «max_tokens» puede ocasionar respuestas excesivamente largas que podrían ser difíciles de manejar o leer para los usuarios. Por el contrario, un valor muy bajo puede dar como resultado respuestas que no proporcionan suficiente información o que se cortan abruptamente.
- Recuerda tener en cuenta el número de tokens en tu prompt al establecer el valor de «max_tokens» para asegurarte de no exceder el límite máximo del modelo.
Temperatura
Es un hiperparámetro que afecta la aleatoriedad de las respuestas del modelo.
- Alta Temperatura: El modelo será más creativo, es decir, generará respuestas más diversas y sorprendentes. Sin embargo, al mismo tiempo, hay una mayor probabilidad de que las respuestas sean menos coherentes o relevantes para el estímulo de entrada. Un valor alto de temperatura puede ser útil para tareas de lluvia de ideas o cuando se busca generar ideas innovadoras.
- Baja Temperatura: El modelo será más determinista y cauteloso. Las respuestas se concentrarán más en las palabras o frases más probables dada la entrada. Esto generalmente resulta en respuestas más predecibles y coherentes, pero puede ser menos creativo. Un valor bajo de temperatura puede ser útil para tareas donde la precisión y relevancia son más importantes que la creatividad.
- Temperatura Intermedia: Proporciona un equilibrio entre coherencia y creatividad. Es útil cuando se desea un poco de ambos elementos.
Por ejemplo, si estás generando un poema, una alta temperatura puede ayudarte a obtener frases más originales. Por otro lado, si estás generando respuestas a preguntas de texto, una baja temperatura probablemente te dará respuestas más precisas.
Recomendaciones de Uso:
- Ajusta la temperatura según tu uso específico de la IA. Si deseas más creatividad, prueba con temperaturas más altas. Si deseas respuestas más coherentes y predecibles, usa temperaturas más bajas.
- Recuerda que incluso con temperaturas bajas, la IA a veces puede generar respuestas inesperadas. Estos modelos son probabilísticos, lo que significa que siempre hay algo de aleatoriedad en sus respuestas.
- Experimenta con diferentes temperaturas para encontrar el equilibrio que funcione mejor para tu aplicación particular.
Top_p
Conocido como ‘muestreo de núcleo’, este hiperparámetro controla la diversidad de las respuestas al seleccionar un subconjunto de tokens posibles para la próxima palabra:
- Top_p Alto: Considera una amplia gama de palabras posibles, aumentando la creatividad de las respuestas.
- Top_p Bajo: Restringe la selección a un grupo más pequeño de palabras, dando como resultado respuestas más predecibles y coherentes.
- Top_p Intermedio: Balancea, diversidad y coherencia.
Recomendaciones de Uso:
- Ajusta el valor de Top_p según busques mayor creatividad o coherencia.
- Evita ajustar simultáneamente Top_p y temperatura, ya que ambos afectan la aleatoriedad de las respuestas y podrían complicar la interpretación de los resultados.
Top_k
Top_k es una técnica utilizada en la generación de texto de IA para limitar las opciones de tokens que puede elegir al generar texto. Con Top_k, el modelo ordena todos los posibles siguientes tokens por su probabilidad y solo considera los ‘k’ tokens más probables para el siguiente paso de generación. Esto significa que las probabilidades de cualquier token por debajo del k-ésimo más probable se eliminan.
El efecto de esto es que reduce la probabilidad de que el modelo genere respuestas que se desvíen del tema, mejorando así la coherencia de las respuestas. Sin embargo, también puede limitar la creatividad del modelo, ya que algunos tokens menos probables, pero potencialmente interesantes o relevantes, se eliminan.
Por ejemplo, si configuras Top_k en 40, el modelo solo considerará los 40 tokens más probables para el siguiente paso de generación.
Recomendaciones de Uso:
- Utiliza Top_k para mejorar la coherencia. Un valor más alto permite más diversidad, mientras que uno más bajo guía las respuestas de manera más restrictiva.
- Experimenta con diferentes valores para encontrar el ajuste adecuado según tus necesidades.
- Un valor de Top_k de 0 significa que este parámetro se ignora y el modelo generará respuestas basadas únicamente en la probabilidad de cada token, sin restricciones adicionales.
Presence Penalty
Presence penalty es un hiperparámetro utilizado en la generación de texto de IA que penaliza o recompensa tokens según si ya han aparecido en el texto. Es una penalización o recompensa que incentiva a la IA a avanzar hacia nuevos temas o a adherirse a los ya mencionados.
- Alta Presence Penalty: El modelo tendrá una fuerte penalización por repetir palabras o puntos, lo que le llevará a generar respuestas con una amplia variedad de palabras y temas. Esto puede ser útil cuando deseas diversidad y creatividad en la generación de texto.
- Baja o Negativa Presence Penalty: El modelo tendrá una baja penalización o incluso una recompensa por repetir palabras o argumentos, lo que le llevará a generar respuestas que pueden repetir ciertas palabras o temas. Esto puede ser útil cuando deseas que el modelo se adhiera más a ciertos temas o cuando deseas incentivar la redundancia para enfatizar un punto.
Recomendaciones de Uso:
- Ajusta el valor de Presence Penalty según tus necesidades. Si buscas diversidad y nuevos temas en la generación de texto, usa un valor alto. Si buscas redundancia y mantenimiento de ciertos puntos, usa un valor bajo o incluso negativo.
- Ten en cuenta que un valor muy alto puede ocasionar una coherencia reducida, ya que el modelo podría estar excesivamente incentivado a avanzar hacia nuevos temas y palabras. De manera similar, un valor muy bajo o negativo puede dar como resultado una repetición excesiva de palabras o temas.
Frequency Penalty
Frequency_penalty es un hiperparámetro en la generación de texto de IA que penaliza tokens según cuántas veces ya han aparecido en el texto. Cuantas más veces aparezcan, más se penalizan. Esto disminuye la probabilidad de que la salida se repita textualmente.
- Alta Frequency Penalty: El modelo tendrá una fuerte penalización por repetir palabras que ya han aparecido varias veces, lo que le llevará a generar respuestas con una amplia variedad de palabras y temas. Esto puede ser útil cuando deseas diversidad en la generación de texto.
- Baja o Negativa Frequency Penalty: El modelo tendrá una baja penalización o incluso una recompensa por repetir palabras que ya han aparecido varias veces, lo que le llevará a generar respuestas que pueden repetir ciertas palabras. Esto puede ser útil cuando deseas incentivar la redundancia para enfatizar un punto.
La diferencia con Presence Penalty:
Mientras que Presence Penalty penaliza o recompensa palabras simplemente por si ya han aparecido en el texto, Frequency Penalty considera cuántas veces han aparecido. Esto significa que Frequency Penalty penalizará más fuertemente las palabras que se repiten frecuentemente, mientras que Presence Penalty aplicará una penalización o recompensa fija sin importar la frecuencia de aparición.
Recomendaciones de Uso:
- Ajusta el valor de Frequency Penalty según tus necesidades. Si buscas diversidad en la generación de texto, usa un valor alto. Si buscas redundancia, usa un valor bajo o incluso negativo.
- Ten en cuenta que un valor muy alto puede ocasionar una coherencia reducida, ya que el modelo podría estar excesivamente incentivado a evitar repetir palabras. De manera similar, un valor muy bajo o negativo puede resultar en una repetición excesiva de palabras.
Stop Sequence
Stop Sequences o stop_sequences son secuencias donde la IA dejará de generar tokens adicionales. Estas son cadenas de texto que, cuando se reconocen en la generación de texto, hacen que el modelo se detenga. Esto puede ser útil para controlar la longitud de la salida generada o para detener la generación cuando se ha alcanzado un cierto punto.
Por ejemplo, puedes usar un punto (‘.’) o una frase específica (‘Fin del informe’) como una secuencia de parada. Cuando el modelo genera uno de estos tokens, se detendrá.
Recomendaciones de Uso:
- Usa secuencias de parada para controlar la longitud y el contenido de las salidas generadas. Si sabes que una cierta frase o carácter debe marcar el final de una respuesta, úsala como una secuencia de parada.
- Recuerda que el modelo debe ‘ver’ la secuencia de parada en su generación para que funcione. Si la secuencia de parada es muy larga o muy inusual, el modelo puede no generarla y, por lo tanto, no detener la generación de texto.
- Aunque es posible especificar múltiples secuencias de parada, no es necesario usar todas. Si solo necesitas una secuencia de parada, eso es perfectamente aceptable.
Conclusión
No todos los modelos tienen todos los parámetros para configurar, de acuerdo al modelo por defecto que elijas tendrás los parámetros disponibles.
Esta guía te ayudará a comprender y utilizar las diferentes configuraciones disponibles en las plantillas de AI Content Labs. Al ajustar estos parámetros, puedes personalizar y optimizar el rendimiento de la IA para satisfacer tus necesidades específicas, asegurando que el contenido generado sea relevante, coherente y adecuado para tu propósito.



